
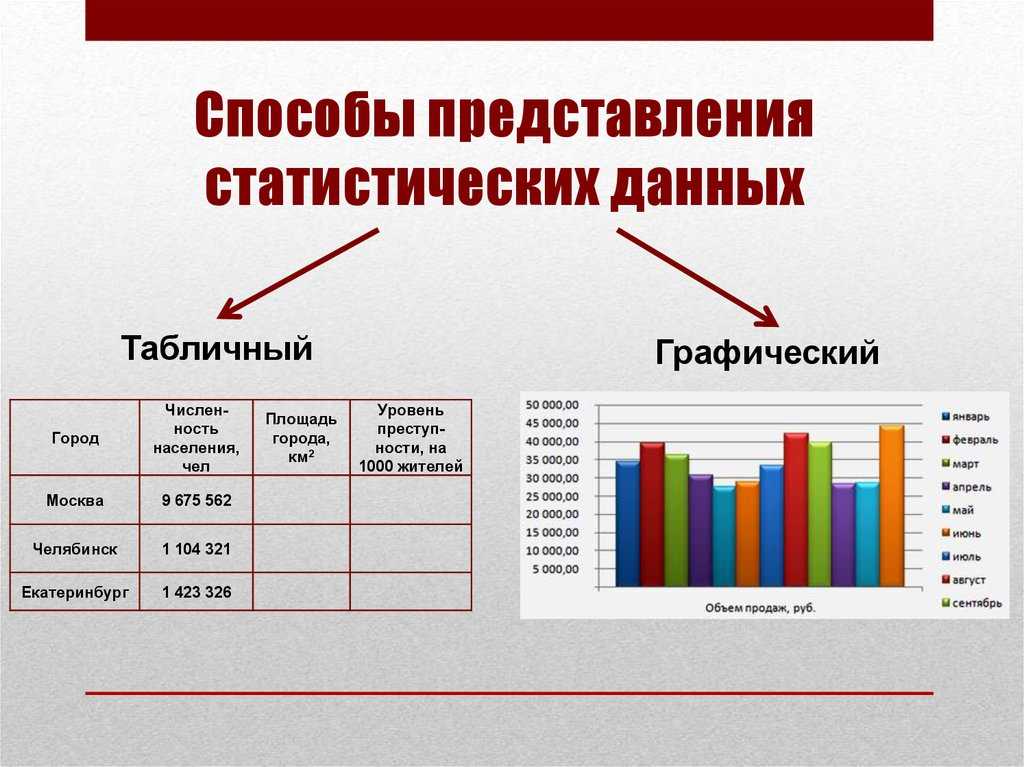
Введение в статистику
Статистика — это наука об изучении данных. Знания в этой области позволяют использовать подходящие методы сбора и анализа данных, а также эффективно представлять результаты такого анализа. Статистика играет ключевую роль в научных открытиях, принятии решений и составлении прогнозов, основанных на данных. Она позволяет гораздо глубже разобраться в объекте исследования.
Чтобы стать успешным специалистом по теории и методам анализа данных, необходимо знать основы статистики. Математика и статистика — “строительные блоки” алгоритмов машинного обучения. Чтобы понимать, как и когда следует использовать различные алгоритмы, нужно знать, какие методы за ними стоят. Тут встаёт вопрос — что именно собой представляет статистика?
Статистика — это математическая наука о сборе, анализе, интерпретации и представлении данных.
Статистический анализ
Применение статистических данных в науке
Статистические данные являются неотъемлемой частью научных исследований. Они позволяют исследователям анализировать, описывать и интерпретировать различные явления и процессы. В науке статистика используется для решения множества задач, включая:
- Сбор данных: Статистические методы позволяют научным работникам собирать информацию и данные, необходимые для проведения исследования. С помощью различных методов сбора данных, таких как опросы, эксперименты или анализ существующих источников, исследователи получают информацию, которая впоследствии будет использована для получения результатов.
- Описание данных: Выполняя описательную статистику, исследователи могут анализировать и систематизировать полученные данные. Они могут вычислить различные меры центральной тенденции (среднее значение, медиану, моду), меры вариации (стандартное отклонение, интерквартильный размах) и другие статистические характеристики. Также исследователи могут представить данные в графической форме с использованием диаграмм и графиков.
- Интерпретация результатов: После описания данных, исследователи приступают к интерпретации полученных результатов. Это включает проверку гипотез, выявление связей и взаимодействий, анализ влияния различных факторов и т.д. Статистические методы позволяют оценивать статистическую значимость полученных результатов и понимать, насколько они обобщаются на всю популяцию.
- Прогнозирование и моделирование: Статистические методы позволяют исследователям строить математические модели и прогнозировать будущие события. На основе анализа исторических данных и выделения закономерностей, исследователи могут создавать модели, которые могут предсказывать результаты будущих событий.
Применение статистических данных в науке позволяет исследователям проводить объективный анализ, делать научные выводы и принимать обоснованные решения. Оно является неотъемлемым компонентом успешного научного исследования.
Литература[]
1. Орлов А.И. Устойчивость в социально-экономических моделях. — М.: Наука, 1979. — 296 с.
2.
3. Орлов А.И. О перестройке статистической науки и её применений. — Журнал «Вестник статистики». 1990. No.1. С.65 — 71.
4.
5.
6. Орлов А.И., Федосеев В.Н. Менеджмент в техносфере: Учебное пособие. – М.: Издательский центр «Академия», 2003. – 384 с.
7.
8. Гнеденко Б.В., Беляев Ю.К., Соловьев А.Д. Математические методы в теории надежности. — М.: Наука, 1965. — 524 с.
9. Гнеденко Б.В., Коваленко И.Н. Введение в теорию массового обслуживания. — М.: Наука, 1966. — 301 с.
10. Нейлор Т. Машинные имитационные эксперименты с моделями экономических систем. – М.: Мир, 1975. — 500 с.
11.
12. Крамер Г. Математические методы статистики. – М.: Мир, 1948 (1-е изд.), 1975 (2-е изд.). – 648 с.
13. Большев Л.Н., Смирнов Н.В. Таблицы математической статистики. — М.: Наука, 1965 (1-е изд.), 1968 (2-е изд.), 1983 (3-е изд.).
14. Смирнов Н.В., Дунин-Барковский И.В. Курс теории вероятностей и математической статистики для технических приложений. Изд. 3-е, стереотипное. – М.: Наука, 1969. – 512 с.
15. Орлов А.И. Математическое обеспечение сертификации: сравнительный анализ диалоговых систем по статистическому контролю. – Журнал «Заводская лаборатория». 1996. Т.62. No.7. С.46-49.
16. Орлов А.И. Распространенная ошибка при использовании критериев Колмогорова и омега-квадрат. – Журнал «Заводская лаборатория».1985. Т.51. No.1. С.60-62.
17. Норман Дрейпер, Гарри Смит Прикладной регрессионный анализ. Множественная регрессия = Applied Regression Analysis. — 3-е изд. — М.: «Диалектика», 2007. — С. 912. ISBN 0-471-17082-8
медиана
Медиана — это значение, которое делит данные на 2 равные части, т. Е. Количество терминов с правой стороны от них равно количеству терминов с левой стороны, когда данные расположены вв порядке возрастания или убывания,
Заметка: Если вы сортируете данные в порядке убывания, это не повлияет на медиану, но IQR будет отрицательным. Мы поговорим об IQR позже в этом блоге.
Медиана будет средним термином, если число терминов нечетное
Медиана будет средним из средних 2 слагаемых, если число слагаемых четное.
Изображение 3
Медиана равна 59, что разделит множество чисел на две равные части. Так как в наборе есть четные числа, ответ — среднее от средних чисел 51 и 67.
Заметка:Когда значения находятся в арифметической прогрессии (разница между последовательными членами постоянна. Здесь она равна 2.),Медиана всегда равна значению,
Изображение 4
Среднее из этих 5 чисел равно 6, а значит, медиана.
Распределение
Внешняя форма данных, выраженная в мерах описательной статистики, даёт нам информацию об их характере. Это как в жизни: по фигуре, походке и одежде человека обычно можно догадаться о его поле, возрасте и даже профессии. В случае числовых данных мы догадываемся о распределении.
Термин пришёл из теории вероятностей, которая рассматривает любое событие в мире как имеющее ту или иную вероятность. Однородные события хоть и происходят с разной вероятностью, но подчиняются распределению, которое «раздаёт» им эти вероятности.
В Data Science распределение понимается обобщённо: это закон соответствия одной величины другой. Оно подсказывает нам, какой именно процесс может скрываться за данными, и то, насколько эти данные полны. Чуть подробнее об этом в нашей статье про математику для джунов.
Возможно, вы уже слышали про колокол нормального распределения, или гауссиану: она описывает процессы, где результат является суммой многих случайных величин, каждая из которых слабо зависит от другой и вносит сравнительно небольшой вклад.
![]()
Распределение размеров чашелистика ириса разноцветного. Изображение: Qwfp / Pbroks13 /
Величина ошибок измерения в физике, длина когтей, зубов и шерсти в биологии, объёмы речных стоков в гидрологии — все эти показатели имеют нормальное распределение. Это, пожалуй, самое распространённое в природе и не только в природе распределение, поэтому оно и названо нормальным.
Распределение Пуассона тоже часто встречается в работе дата-сайентистов и аналитиков: это число событий за какой-то промежуток времени — при условии, что события независимы друг от друга и имеют некоторый порог интенсивности.
![]()
При ƛ = 10 горка Пуассона похожа на колокол Гаусса. Будьте внимательны!
Это и число посетителей в торговом центре, и количество голов, забитых футбольной командой, и скорость роста колонии бактерий.
Существуют и , в том числе довольно экзотические: Вигнера, Вейбулла, Коши. Они встречаются намного реже или преимущественно в каких-то специальных областях вроде квантовой физики. Тем не менее дата-сайентисту нужно знать графики, параметры и названия основных распределений, благо их не так много.




Статистические методы анализа данных как область научно-практической деятельности[]
Статистические методы анализа данных применяются практически во всех областях деятельности человека. Их используют всегда, когда необходимо получить и обосновать какие-либо суждения о группе (объектов или субъектов) с некоторой внутренней неоднородностью.
Целесообразно выделить три вида научной и прикладной деятельности в области статистических методов анализа данных (по степени специфичности методов, сопряженной с погруженностью в конкретные проблемы):
а) разработка и исследование методов общего назначения, без учета специфики области применения;
б) разработка и исследование статистических моделей реальных явлений и процессов в соответствии с потребностями той или иной области деятельности;
в) применение статистических методов и моделей для статистического анализа конкретных данных.
Кратко рассмотрим три только что выделенческих методов и моделей, предназначенных для определенной области применения, может быть весьма сложным и математизированным (см., например, монографию ), с другой — результаты представляют не всеобщий интерес, а лишь для некоторой группы специалистов. Можно сказать, что работы вида б) нацелены на решение типовых задач конкретной области применения.
Режим
Режим — это термин, отображающий максимальное время в наборе данных, то есть термин, который имеет наибольшую частоту.
Изображение 5
В этом наборе данных режим равен 67, потому что он имеет больше, чем остальные значения, то есть в два раза.
Но может быть набор данных, в котором нет режима вообще, поскольку все значения появляются одинаковое количество раз. Если два значения появились одновременно и больше, чем остальные значения, то набор данныхбимодальный, Если три значения появились одновременно и больше, чем остальные значения, тогда набор данныхтримодальныйи для n режимов этот набор данныхмультимодальные,
О высоких статистических технологиях[]
Термин «высокие технологии» популярен в современной научно-технической литературе. Он используется для обозначения наиболее передовых технологий, опирающихся на последние достижения научно-технического прогресса. Есть такие технологии и среди технологий статистического анализа данных — как в любой интенсивно развивающейся научно-практической области. Они подробно обсуждаются в настоящем учебнике. Их роль подчеркнута тем, что термин «высокие статистические технологии» вынесен в название учебника.
Обсудим этот пока не вполне привычный термин (он был введен в статье , опубликованной в 2003 г.). Каждое из трех слов ны в соответствии с нею (а не являются т.н. эвристическими).
Термин «статистические» привычен. Статистические данные – это результаты измерений, наблюдений, испытаний, анализов, опытов, а «статистические технологии» — это технологии анализа статистических данных.
Наконец, сравнительно редко используемый применительно к статистике термин «технологии». Статистический анализ данных, как правило, включает в себя целый ряд процедур и алгоритмов, выполняемых последовательно, параллельно или по более сложной схеме. В частности, можно выделить следующие этапы:
— планирование статистического исследования;
— организация сбора необходимых статистических данных по оптимальной или рациональной программе (планирование выборки, создание организационной структуры и подбор команды статистиков, подготовка кадров, которые будут заниматься сбором данных, а также контролеров данных и т.п.);
— непосредственный сбор данных и их фиксация на тех или иных носителях (с контролем качества сбора и отбраковкой ошибочных данных по соображениям предметной области);
— первичное описание данных (расчет различных выборочных характеристик, функций распределения, непараметрических оцеей гипотезы),
— более углубленное изучение, т.е. применение различных алгоритмов многомерного статистического анализа, алгоритмов диагностики и построения классификации, статистики нечисловых и интервальных данных, анализа временных рядов и др.;
— проверка устойчивости полученных оценок и выводов относительно допустимых отклонений исходных данных и предпосылок используемых вероятностно-статистических моделей, в частности, изучение свойств оценок методом размножения выборок;
— применение полученных статистических результатов в прикладных целях (например, для диагностики конкретных материалов, построения прогнозов, выбора инвестиционного проекта из предложенных вариантов, нахождения оптимальных режима осуществления технологического процесса, подведения итогов испытаний образцов технических устройств и др.),
— составление итоговых отчетото информационный технологический процесс, другими словами, та или иная информационная технология. Статистическая информация подвергается разнообразным операциям (последовательно, параллельно или по более сложным схемам). В настоящее время об автоматизации всего процесса статистического анализа данных говорить было бы несерьезно, поскольку имеется слишком много нерешенных проблем, вызывающих дискуссии среди статистиков.
Меры описательной статистики
Задача описательной статистики, как следует из названия, — дать хорошее описание данных. Она не для предсказаний, выводов или преобразований — только внешняя форма данных, измеренная в показателях.
Ключевые показатели, применяемые в описательной статистике (их ещё называют мерами или, если точнее, ), — это:
- Среднее: чаще всего вычисляется как среднее арифметическое. Просто складываем все значения, делим на их количество — и вуаля, средняя температура по больнице готова.
- Медиана: если выстроить все данные по возрастанию и найти середину этого ряда, это как раз и будет медиана. Одна половина из значений данных будет больше медианы, а другая — меньше.
- Мода: значение в наборе данных, которое встречается чаще всего. Запомнить очень легко: мода — самое популярное из значений, то, что «носят все».
![]()
Посмотрите это небольшое видео о среднем, медиане и моде на сайте Академии Хана — образовательного ресурса, который славится доходчивыми объяснениями. Там всё просто, на понятном русском языке.
Кроме трёх перечисленных, есть и другие статистические показатели — например, . Главная из них — дисперсия, о ней ниже. Все они нужны, чтобы понять, какие перед нами данные и о чём именно они рассказывают.
Программное обеспечение статистических методов[]
В настоящее время статистическая обработка данных проводится, как правило, с помощью соответствующих программных продуктов. Мы не сочли целесообразным приводить ссылки на те или иные пакеты программ по нескольким причинам.
Во-первых, популяции программных продуктов быстро обновляются. Пакеты программ, разработанные 10-15 лет назад, безнадежно устарели. Новые версии, как правило, весьма отличаются от предшественников десятилетней давности. В то же время лучшие книги 40-60-х годов по статистическим методам остаются актуальными и сейчас. Например, монографии .
Во-вторых, каждый программный продукт обладает определенными достоинствами и недостатками. Как показывает опыт , при сравнении нескольких пакетов программ крайне трудно сделать обоснованный вывод о том, какой из них следует предпочесть.
Необходимо отметить, что между математической и прикладной статистикой имеется и с течением времени углубляется разрыв. Он проявляется, в частности, в том, что большинство методов, включенных в статистические и SPSS или в более новую систему Statistica), даже не упоминается в учебниках по математической стистике. В результате разрыва специалист по математической статистике оказывается зачастую беспомощным при обработке реальных данных, а пакеты программ применяют (что еще хуже — и разрабатывают) лица, не имеющие необходимой теоретической подготовки. Естественно, что они допускают разнообразные ошибки. Типовые ошибки при применении критериев согласия Колмогорова и омега-квадрат давно проаналваны в литературе (например, в статье 1985 г. и учебнике ). Об удручающих результатах анализа государственных стандартов по статистическим методам управления качеством рассказ
По оценкам экспертов, распространенные статистические пакеты программ обычно соответствуют уровню научных исследований 60-70-х годов. В них нет большинства статистических методов, включенных в современные учебники . Впрочем, как показывает практика преподавания, студенты и слушатели легко реализуют новые статистические методы с помощью подручных вычислительных средств.
Для чего изучать статистику?
Один из основных принципов науки о данных — получение выводов из их анализа. Статистика отлично для этого подходит. Она является разновидностью математики и использует формулы, но она отнюдь не обязательно покажется пугающей, даже если вам не приходилось сталкиваться с ней раньше.
Машинное обучение зародилось из статистики. Основой используемых в нём алгоритмов и моделей является так называемое статистическое обучение. Знание основ статистики крайне полезно вне зависимости от того, изучаете вы глубоко алгоритмы МО или просто хотите быть в курсе новейших исследований в этой сфере.
Корреляция
Когда изменения одной величины сопутствуют изменениям другой, говорят о корреляции. Главное, что необходимо о ней знать: корреляция не означает причинно-следственную связь.
Линейная корреляция — это когда изменения одной величины пропорциональны изменениям другой. Она может быть:
- положительной — обе величины растут в одну сторону;
- отрицательной — одна величина растёт, другая уменьшается;
- а также сильной или слабой, независимо от направления.
![]()
Изображение: Freie Universität Berlin
Статистическую связь между переменными исследуют с помощью . Его основная задача — оценить тесноту связи (это термин) между переменными, чтобы понять, какие переменные учитывать в модели, а какие нет.
И ещё раз, потому что действительно важно: корреляция ни в коем случае не означает причинно-следственную связь. Если два показателя скоррелированы, то далеко не факт, что они хоть как-то связаны
Кстати, проект Spurious Correlations («Ложные корреляции») публикует графики корреляций между совершенно неожиданными статистическими показателями — например, количеством людей, утонувших в домашних бассейнах, и числом фильмов с участием Николаса Кейджа.
![]()
Возраст победительниц конкурса «Мисс Америка» и количество убийств, совершённых с помощью пара и горячих предметов. Изображение: Tyler Vigen / Spurious Correlations
Имеет смысл время от времени заходить по этой ссылке с целью профилактики СПГС — синдрома поиска глубинной связи.
Смещение
Аналогично тому, как производится выборка из генеральной совокупности, дата-сайентисты из готового датасета выделяют тренировочный набор. Именно на этой «выборке второго порядка» модель учится делать предсказания.

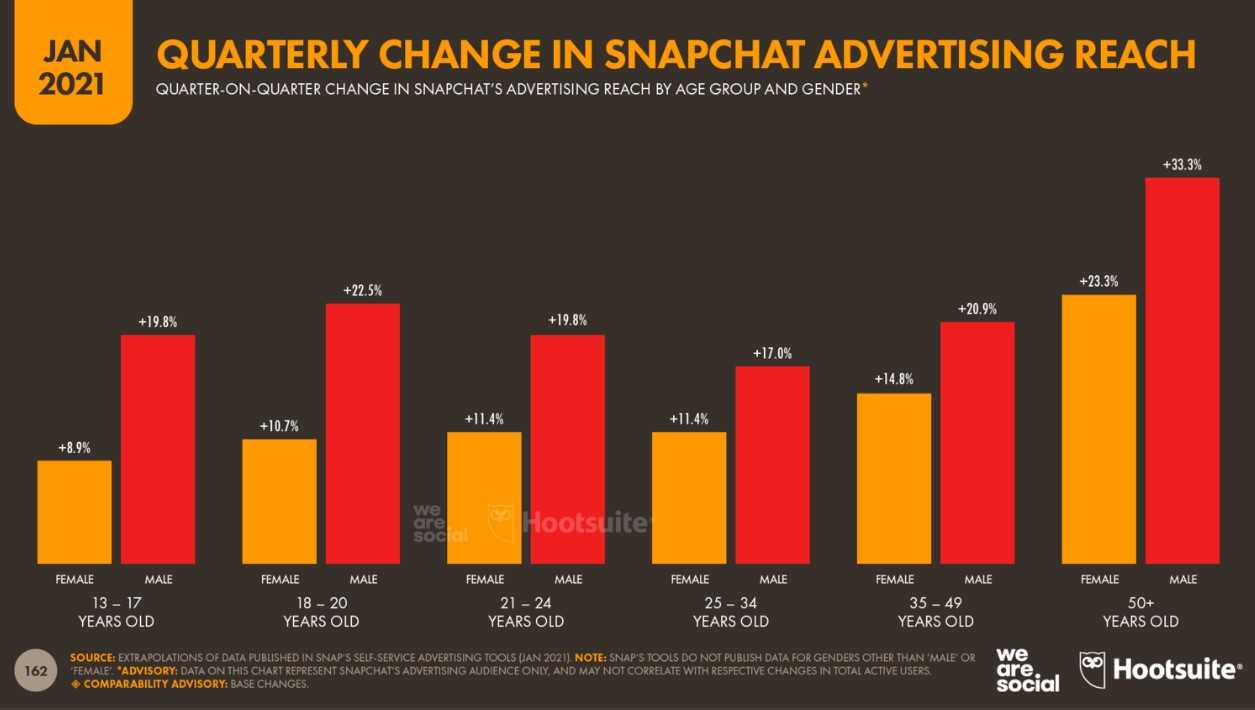
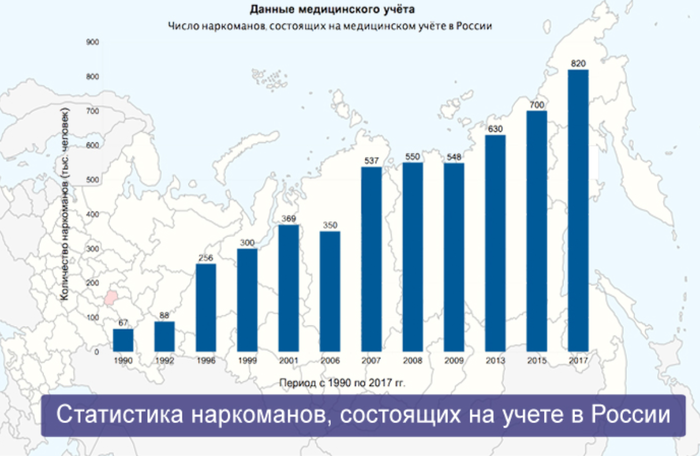

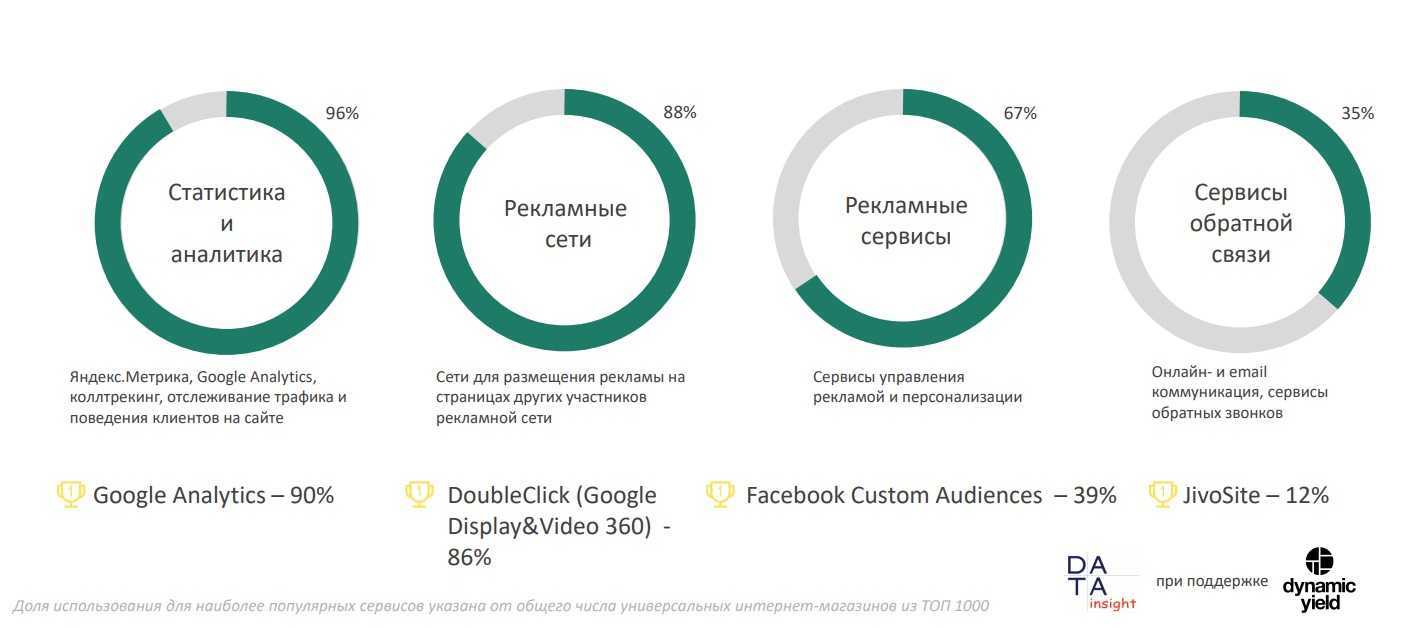
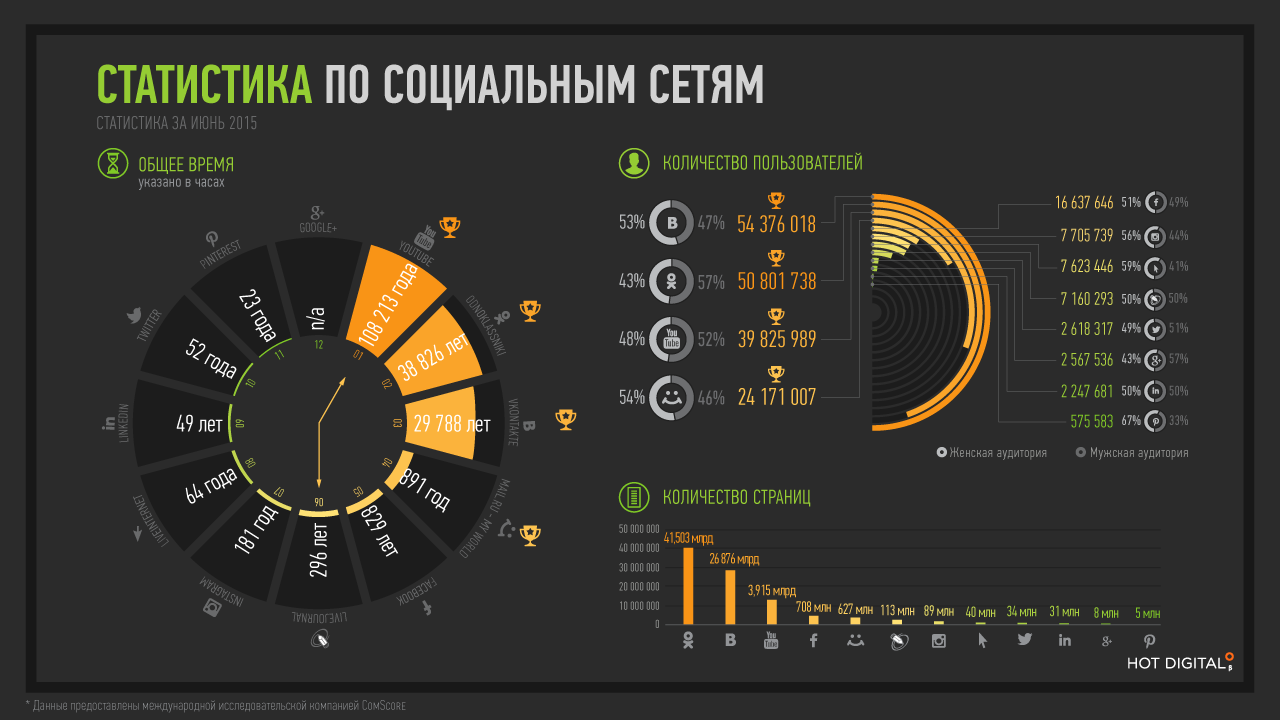
Прочитайте нашу статью о создании простой модели машинного обучения. Она предсказывает город, в который вероятнее всего поедет турист, на основании его возраста, пола, места жительства, дохода и транспортных предпочтений. Такая рекомендательная система на минималках.
Смещение происходит, когда модель недооценивает или переоценивает какой-либо параметр. Представим, что модель из статьи выше отправляет всех краснодарцев в Париж — независимо от их дохода, предпочтений и других параметров. В этом случае мы скажем, что модель переоценивает значение параметра «Город проживания».
![]()
Чаще всего причиной смещения являются:
- неправильный сбор данных в датасет: например, в него попали только краснодарцы — любители Парижа;
- неправильное формирование тренировочного набора из датасета;
- неправильное измерение ошибок.
Когда мы неверно собираем данные, говорят о систематической ошибке отбора. Например, в прошлом веке многие считали, что во Вселенной больше голубых галактик, — впечатление возникало потому, что плёнка была более чувствительна к голубой части спектра.
![]()
О доброте дельфинов мы знаем только от спасённых ими людей. Фото: Pixabay
Другая ошибка — ошибка меткого стрелка — происходит, когда мы вольно или невольно отбираем в выборку только схожие между собой данные, то есть фактически рисуем мишень вокруг места, куда попадём.
Причин, вызывающих смещение, так много, что Марк Твен заметил: «Существует три вида лжи: ложь, наглая ложь и статистика». Например:
- Эффект низкой/высокой базы. Если в финансовом отчёте найти самый низкий показатель прибыли, то на его фоне любой другой результат будет выглядеть как достижение. И наоборот: если хотите показать, что ученик перестал прогрессировать, сравнивайте текущие оценки с его лучшими результатами за все годы обучения.
- Сокращение рассматриваемого периода. Если хочется доказать, что рекламная кампания не приносит результатов, надо просто найти период, когда деньги уже потрачены, а эффекта ещё нет. И рассматривать только его.
- Исключение из выборки. Если вы измеряете результативность методики снижения веса, то можно выкидывать из выборки участников, которые отказались от методики, не дойдя до конца. Это существенно «повысит» эффективность методики.
- Ну и, конечно же, классика: «Интернет-опрос населения показал, что 100% населения пользуются интернетом».
Эти и другие ошибки смещения трудно выявить статистическими методами, поэтому нужно стараться избежать их до того, как вы начнёте сбор данных.
Если пить «Боржоми» уже поздно (датасет уже сформирован), обязательно спросите себя: «Не смещены ли мои данные?» — а они наверняка смещены, «Куда и почему они смещены?» и «Можно ли с этим жить?»
Определение статистических данных
Статистические данные представляют собой числовую информацию, полученную в результате сбора и обработки данных, связанных с определенным явлением или событием. Они позволяют описать, анализировать и интерпретировать различные аспекты реальности с помощью математических методов и моделей.
Статистические данные могут быть представлены в виде таблиц, диаграмм, графиков или просто списком чисел. Они могут описывать различные характеристики, такие как количество, частотность, среднее значение, медиана, дисперсия и т.д.
Сбор статистических данных проводится с помощью различных методов, таких как анкетирование, наблюдение, эксперименты и другие. После сбора данные подвергаются статистической обработке, которая включает в себя анализ, интерпретацию и выводы о рассматриваемом явлении или событии.
Статистические данные широко используются в различных областях деятельности, включая науку, экономику, социологию, медицину и многие другие. Они позволяют проводить исследования, анализировать тенденции, прогнозировать развитие событий, принимать решения и решать задачи на основе фактических данных и вероятностного подхода.
Качественные
Также есть качественные данные. Они менее гибкие при анализе, особенно если планируется работа с числами и подобной информацией. Представляют собой характеристики, которые описываются. С помощью таких сведений составляют непосредственное описание наблюдений, характеристик, параметров.
Информация, которую хранят качественные данные в переменной, трудно измеримы. Полученные результаты будут субъективными. Примеры: вкусовые предпочтения, семейное положение, цвет самоката. Данная категория носит название категориальной.
Номинальные
У качественных данных тоже есть своя классификация. Первый вариант – это номинальный вид. Он выражает дискретные единицы, помогает обозначать переменные, не имеющие количественных выражений.
Номинальные качественные данные не имеют никакого порядка. При изменении их «положения» во время исследований результаты не меняются. Для визуализации лучше всего использовать круговые и столбчатые диаграммы. А для обработки информации чаще применяется прямое кодирование. Оно помогает провести преобразования для формирования числовых свойств.
Порядковые качественные
Порядковые качественные данные – сочетание числовых и категориальных сведений. «Измерения» можно разбить на различные категории, но числа, ассоциирующиеся с каждым вариантом, обладают значением.
Пример – рейтинги общепита. Здесь:
- 0 – это самая низкая оценка;
- 5 – самая высокая.
Обрабатываются такие материалы в качестве категориальных (количественных), если при построении диаграмм и графиков подразделяются на конкретные, упорядоченные блоки/группы.
Порядковые сведения – это почти то же самое, что и номинальные качественные, но здесь порядок имеет значение. Для визуализации лучше использовать шкалы.
Обобщаются качественные порядковые данные при помощи:
- частности;
- процентных долей;
- диаграмм.
Допускается использование процентиля, медианы, моды, межквартального размаха.
Бинарные
Рассматривая качественные и количественные данные, стоит обратить внимание на еще один вариант. Он относится к категориальным
Речь идет о бинарном типе сведений.
Такой вариант широко известен в программировании. Качественные сведения будут принимать только две интерпретации – «да» и «нет». Подобные «ответы» представлены в виде:
- истины и лжи;
- 1 и 0.
Бинарные качественные сведения широко применяются в машинном обучении. В качестве примера можно привести любой вопрос, на который отвечают «да» или «нет»: помыл ли человек машину, забрал ли детей из сада.
Быстрее разобраться в статистике, качественных и количественных данных, машинном обучении помогут специализированные дистанционные компьютерные курсы. Они рассчитаны на срок от нескольких месяцев до года. Подобрать направление можно с учетом желаний, потребностей и навыков. В конце выдается электронный сертификат, подтверждающий знания человека. Освоить инновационное IT-направление еще никогда не было настолько легко и интересно.
Применение статистических данных в экономике
Статистические данные играют важную роль в экономике, обеспечивая необходимую информацию для анализа и принятия решений. Они помогают понять состояние экономики, развить стратегии и прогнозировать будущие тенденции и тренды.
Одним из основных применений статистических данных в экономике является анализ макроэкономических показателей. Статистические данные позволяют измерить и оценить различные аспекты экономики, такие как валовый внутренний продукт (ВВП), инфляция, безработица, объемы производства и потребления и другие.
Данные о ВВП, например, позволяют определить общую стоимость товаров и услуг, произведенных в определенной стране за определенный период времени. Эта информация позволяет оценить экономический рост страны и прогнозировать будущее развитие.
Статистические данные также используются для изучения рыночной динамики. Они позволяют анализировать спрос и предложение, рост или спад рынков, изменение цен и другие параметры, которые могут влиять на поведение потребителей и инвесторов.
Экономисты и бизнес-аналитики используют статистические данные для разработки стратегий и принятия решений. Они могут исследовать прошлые данные и тренды, чтобы понять, какие факторы влияют на рынок и какие действия необходимо предпринять для достижения желаемых результатов.
Статистические данные также помогают в принятии инвестиционных решений и управлении рисками. Они позволяют анализировать производительность активов, оценивать финансовые рынки, определять вероятность убытков и прогнозировать доходность инвестиций.
Еще одно важное применение статистических данных в экономике — изучение экономической неравенности. Они позволяют определить различия в доходах и состоянии населения, изучать факторы, которые влияют на неравенство, и разрабатывать политики, направленные на снижение неравенства и обеспечение социальной справедливости
Наконец, статистические данные имеют большое значение для мониторинга и оценки эффективности государственных программ и политик. Они позволяют оценить результаты и эффективность финансовых мер, таких как налоговые скидки или субсидии, и принять меры для их корректировки, если необходимо.
Пример использования статистической информации в экономике
Область применения
Статистические данные
Анализ макроэкономических показателей
ВВП, инфляция, безработица
Изучение рыночной динамики
Цены, объемы производства и потребления
Разработка стратегий и принятие решений
Прошлые данные и тренды
Инвестиционные решения и управление рисками
Производительность активов, финансовые рынки
Изучение экономической неравенности
Различия в доходах и состоянии населения
Мониторинг и оценка государственных программ и политик
Результаты и эффективность финансовых мер
Найдено научных статей по теме — 15
Определение коэффициента капитализации по статистическим данным
Ласкин Михаил Борисович, Русаков Олег Витальевич, Джаксумбаева Ольга Ильинична
Авторами статьи предложен метод опреде-ления коэффициента капитализации, оценки стоимости недвижимости, оценки рентных ставок на основании стохастической модели ценообразования.
Методы обработки статистических данных в правовых исследованиях
Архангельская Екатерина Владиславовна
Статья посвящена анализу возможностей статистической обработки информации о преступлениях на компьютере. Изложены способы, доступные для обработки данных, представленных в виде таблиц, с помощью функций, формул и диаграмм.


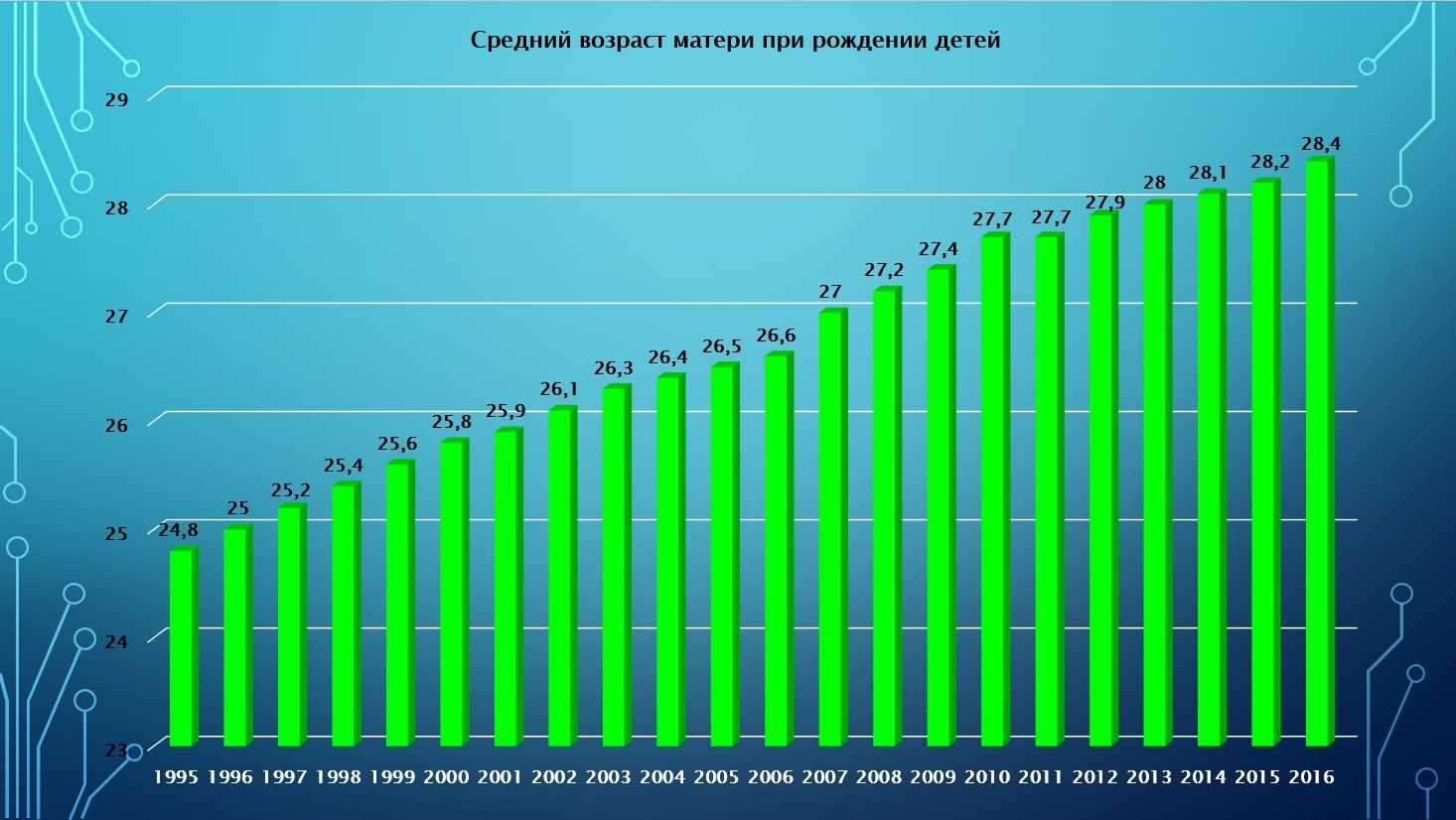
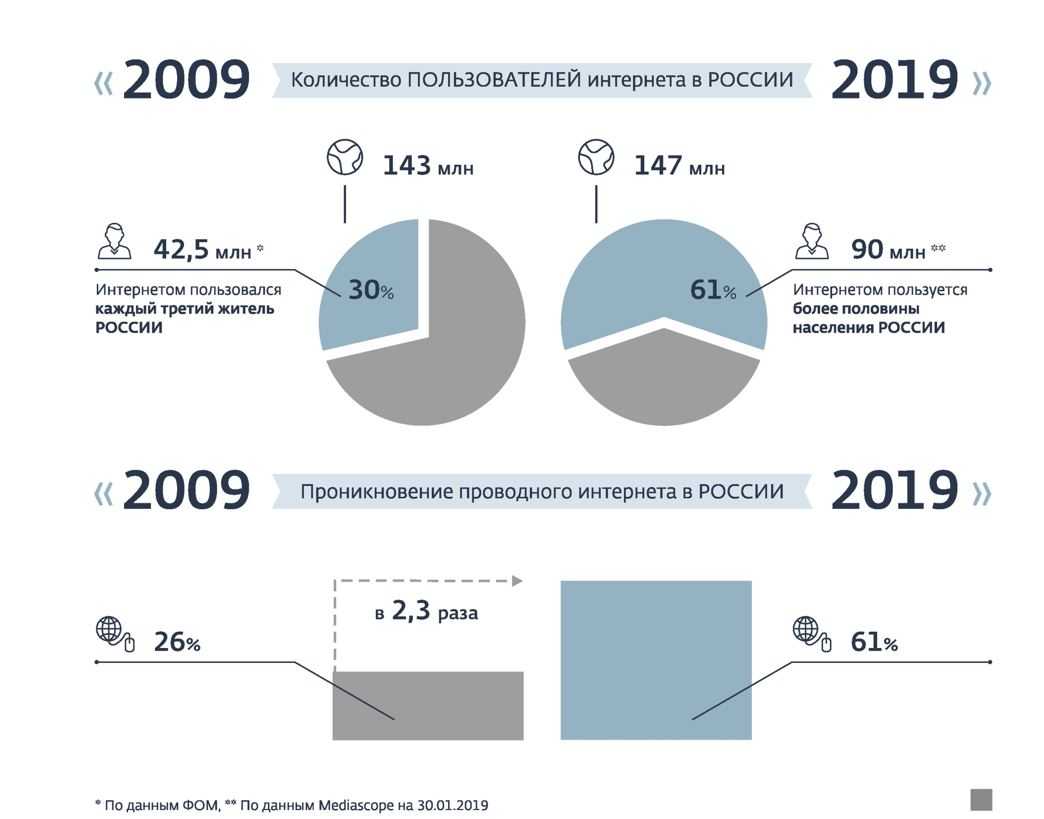
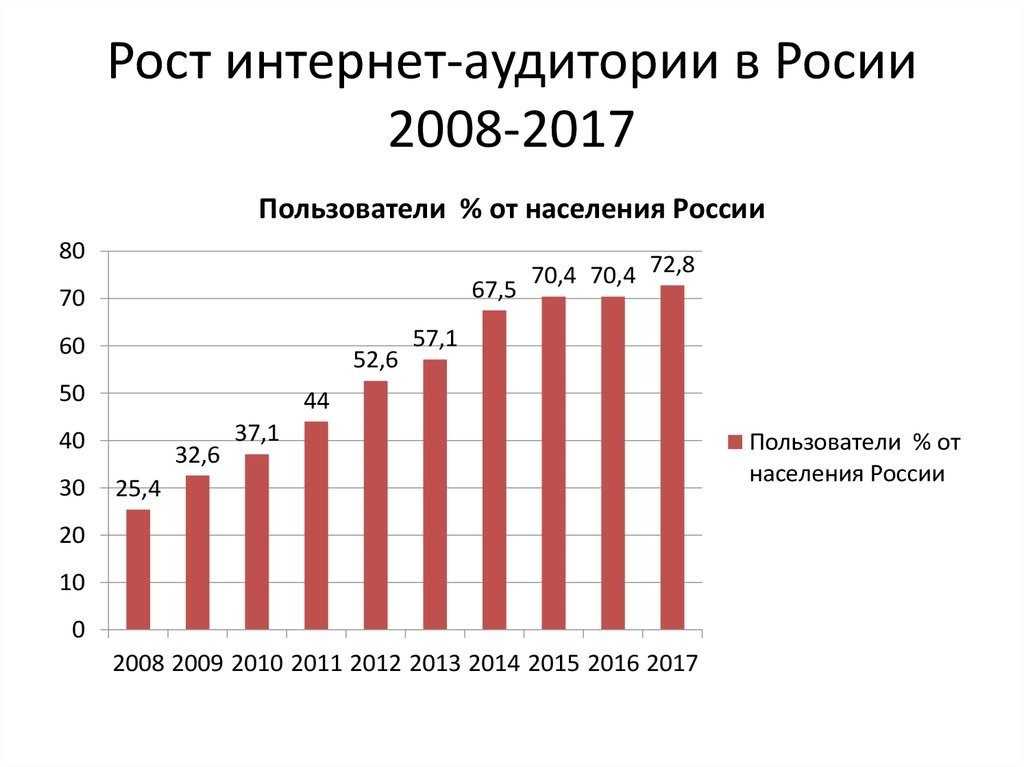

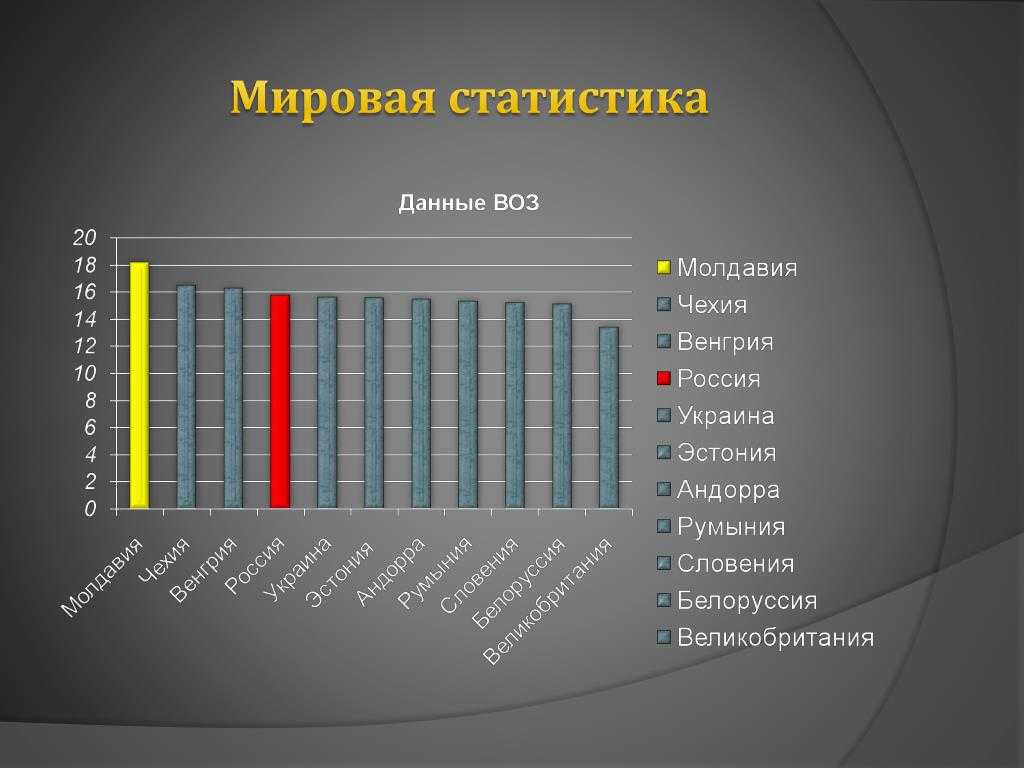
Проблема выбора статистических данных при анализе странового риска
Сусанов Д.Ю.
Любое научное исследование может привести к неверным результатам или вообще стать бессмысленным, если базируется на неточных исходных данных.
Информационная база прогнозирования, требования к статистическим данным
Попков Сергей Юрьевич
В предполагаемой статье раскрываются основные требования к финансовому прогнозированию, анализируется современная налоговая система, а также основные характеристики бюджета.
Проблемы сопоставимости статистических данных о внешней торговле России
Сельцовский Вячеслав Леонович
В статье раскрыты основные изменения в методологии статистического учета внешней торговли Российской Федерации с 1991 года. Оценено их влияние на статистические данные о торговом обороте России.
Семья с одним родителем в Калмыкии (на материалах статистических данных)
Нусхаева Байрта Басанговна
Рассмотрена одна из моделей семьи семья с одним родителем, которая в последние десятилетия находит все большее распространение.
Статистические подходы к анализу и прогнозированию демографических данных
Копнова Е.Д., Родионова Л.А.
В статье рассмотрены возможности применения ARIMA-моделирования к анализу и прогнозированию временных рядов демографических показателей.
Оценка достоверности статистических данных по численности населения России
Ольхов Александр Александрович
Приведены результаты анализа демографической ситуации в России в динамике за 2006-2010 гг., а также представлен прогноз изменения численности населения до 2030 г.
Эвристический метод группирования объектов на основе статистических данных
Борисов Александр Николаевич
На основе примеров демонстрируется эвристический метод группирования «схожих» объектов, использующий измененное представление графических результатов обработки статистических данных на базе табличного процессора Ms Excel.
Роль предварительной подготовки исходных данных для статистического анализа
Борисов А. Н.
Рассматривается необходимость предварительной неформальной подготовки данных, предназначенных для последующего статистического анализа.
Статистические данные, характеризующие финансирование образовательной системы
В этом номере представлена информация об объемах государственных инвестиций в образование, приводится их сравнение с валовым внутренним продуктом (ВВП).
Исследование статистических данных методами корреляционно-регрессионного анализа
Бажанов В.Ю., Кравченко Ю.А.
В статье дается оценка хозяйственной деятельности тыловых подразделений в системе органов внутренних дел. Показано влияние статей финансирования на состояние преступности.
Динамика экономического развития регионов России: по данным статистического анализа
Баранов Сергей Владимирович
Проводится методика оценки межрегиональной дифференциации. Проведен статистический анализ специфики экономического развития регионов Севера в сравнении с общероссийской ситуацией.
Заключение
Из этой статьи вы узнали о различных типах данных, используемых в статистике, о разнице между дискретными и непрерывными данными, а также о том, что собой представляют номинальные, порядковые, бинарные, интервальные данные и данные соотношения. Кроме того, теперь вы знаете, какие статистические измерения и методы визуализации можно применять для разных типов данных и как преобразовать категориальные переменные в числовые. Это позволит вам провести большую часть разведочного анализа на представленном наборе данных.
- Продвинутый взгляд на рекурсию
- Не учите машинное обучение
- Инновационный алгоритм глубокого обучения в Google Translate
Читайте нас в Telegram, VK и
Перевод статьи Jagadish Bolla: Data Types in Statistics Used for Machine Learning
Заключение
Data Science — не просто комбинирование модных моделей в Jupyter-ноутбуке. Профессионалы в этой области глубоко понимают природу данных и то, как они могут помочь в принятии конкретных бизнес-решений.
Всё это изучалось в статистике задолго до того, как первый дата-сайентист набрал свой первый import pandas as pd. Статистика — фундамент всей современной науки о данных, включая машинное обучение, глубокие нейросети и даже искусственный интеллект.
В нашем курсе «Профессия Data Scientist» статистике уделено самое пристальное внимание. Вы не ударите в грязь лицом ни на тусовке статистиков, ни на настоящем DS-собеседовании
Приходите!